Command Line Kung Fu
The shell, and why
you should care
Brian Dailey (@byeliad)
The Shell
Evolved from a text only environment.
$ input
output
$ input
output
You
▲
▼
Shell
▲
▼
Computer
It's A Little Terse
1 tr -cs A-Za-z '\n' |
2 tr A-Z a-z |
3 sort |
4 uniq -c |
5 sort -rn |
6 sed ${1}q
Some might say "Cryptic"
To the unitiated, it might seem..
An enigma...
Wrapped in a mystery.

Swallowed by a Chupacabra

Eaten by a Deep Crow
Consumed by Cthulhu
However, once you spend some time with it,
you'll see it's not really all that scary.
You need not look like a wizard to be a CLUI wizard.

So let's talk about what makes it worth your time.
Unix Philosophy
"Although [this] philosophy can't be written down in a single sentence, at its heart is the idea that the power of a system comes more from the relationships among programs than from the programs themselves. Many UNIX programs do quite trivial things in isolation, but, combined with other programs, become general and useful tools."
— The Unix Programming Environment
Relationships > Programs
Modularity

4 Tenets
1.
Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new features.
2.
Expect the output of every program to become the input to another, as yet unknown, program. Don't clutter output with extraneous information. Avoid stringently columnar or binary input formats. Don't insist on interactive input.
3.
Design and build software, even operating systems, to be tried early, ideally within weeks. Don't hesitate to throw away the clumsy parts and rebuild them.
4.
Use tools in preference to unskilled help to lighten a programming task, even if you have to detour to build the tools and expect to throw some of them out after you've finished using them.
So what does all of this mean for me?
Every *nix tool you learn multiplies the
usefulness of the ones you already know.
"Read a file of text, determine the n most frequently used words, and print out a sorted list of those words along with their frequencies."
1 tr -cs A-Za-z '\n' |
2 tr A-Z a-z |
3 sort |
4 uniq -c |
5 sort -rn |
6 sed ${1}q
"If you are not a UNIX adept, you may need a little explanation, but not much, to understand this pipeline of processes. The plan is easy:"
1 tr -cs A-Za-z '\n' |
2 tr A-Z a-z |
3 sort |
- Make one-word lines by transliterating the complement (-c) of the alphabet into newlines (note the quoted newline), and squeezing out (-s) multiple newlines.
- Transliterate upper case to lower case.
- Sort to bring identical words together.
4 uniq -c |
5 sort -rn |
6 sed ${1}q
- Replace each run of duplicate words with a single representative and include a count (-c).
- Sort in reverse (-r) numeric (-n) order.
- Pass through a stream editor; quit (q) after printing the number of lines designated by the script’s first parameter (${1}).
More reasons...
Reason's not to...

Advanced Beginner,
Competent,
Or Proficient?
So where do I start?
- Amazon EC2 instance w/ Ubuntu
- Ubuntu Live CD
- Mac OS X + homebrew
- Cygwin (if you must)
Getting Around
Moving the cursor:
Ctrl + a Go to the beginning of the line (Home) Ctrl + e Go to the End of the line (End) Ctrl + p Previous command (Up arrow) Ctrl + n Next command (Down arrow) Alt + b Back (left) one word Alt + f Forward (right) one word Ctrl + f Forward one character Ctrl + b Backward one character Ctrl + xx Toggle between the start of line and current cursor position
Editing:
Ctrl + L Clear the Screen, similar to the clear command Ctrl + u Cut/delete the line before the cursor position. Alt + Del Delete the Word before the cursor. Alt + d Delete the Word after the cursor. Ctrl + d Delete character under the cursor Ctrl + h Delete character before the cursor (backspace) Ctrl + w Cut the Word before the cursor to the clipboard. Ctrl + k Cut the Line after the cursor to the clipboard. Alt + t Swap current word with previous Ctrl + t Swap the last two characters before the cursor (typo). Esc + t Swap the last two words before the cursor. ctrl + y Paste the last thing to be cut (yank) Alt + r Cancel the changes and put back the line as it was in the history (revert). ctrl + _ Undo
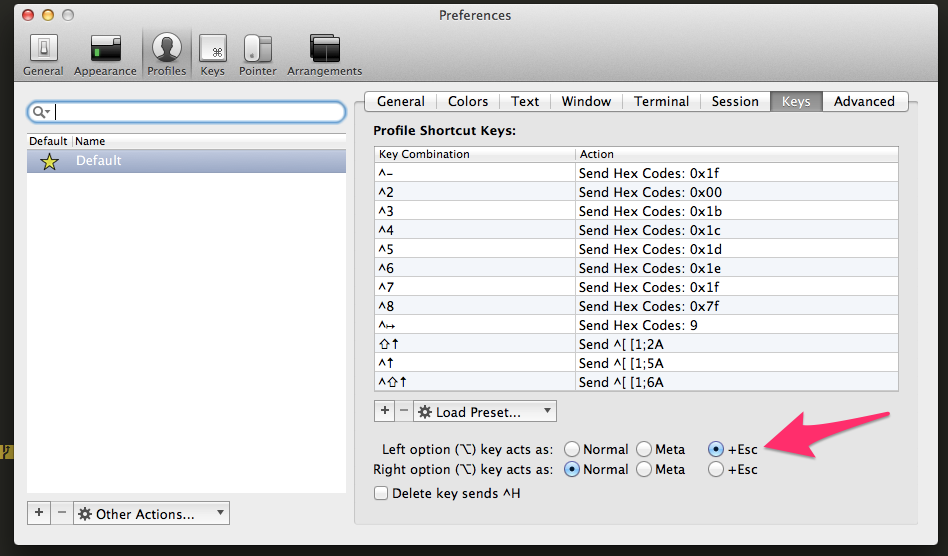
Shell it Live!
Hope I don't screw it up!
Where do all of these shortcuts come from?
GNU Readline Library
Things you also get...
Tab Completion
$ ls Gr[tab] $ ls Gruntfile.js $ ls i[tab][tab] img/ index.html $ git commit [tab] $ git commit index.html
GNU History Library
Ctrl + r Search back through history Ctrl + s Search forward through history Alt + . Use the last word of the previous command Ctrl + g Escape from history searching mode
On argument reuse...
!! Rerun previous command. !l Rerun previous command starting with 'l' !l:p Print (don't execute) last command starting with 'l' !$ Last argument in previous command. !* All arguments in previous command.
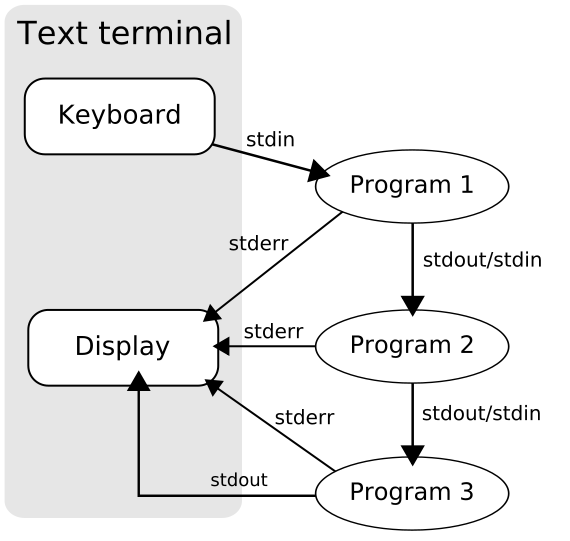
Redirecting

Source: Wikipedia
{kind=link}
stdout to file
# sort lines and write to a file
sort myfile.txt > sorted_myfile.txt
# same as above, but append to existing file.
$ sort myfile2.txt >> sorted_myfile.txt
file to stdin
# sort lines and print to stdout
$ sort < myfile.txt
# same, but let's print to a file.
$ sort < myfile.txt > sorted_myfile.txt
|
# Grab first line, replace tabs with line
# return, and paginate with numbers.
head -1 FLAT_RCL.txt | tr "\t" "\n" | less -N
Shell it Live!
Pipes: How do they work?
- Each command spawns its own process.
- First program starts to push to stdout until it hits a buffer limit (imposed by your shell of choice).
- As soon as it hits the limit, the process is blocked.
- First filter process starts reading stdin, and incrementally starts passing stdout to the next process.
- Some filters must wait until the entire output is available (e.g., sort) before they can continue, which can buffer to disk.
- Continues until the last process is reached.
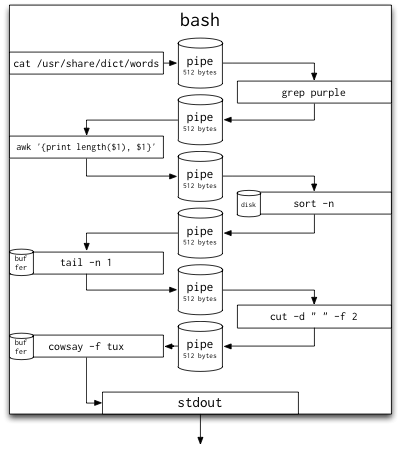
Example from Peter Sobot
cat /usr/share/dict/words | # Read in the system's dictionary.
grep purple | # Find words containing 'purple'
awk '{print length($1), $1}' | # Count the letters in each word
sort -n | # Sort lines ("${length} ${word}")
tail -n 1 | # Take the last line of the input
cut -d " " -f 2 | # Take the second part of each line
cowsay -f tux # Print resulting word
Print out longest word containing 'purple'
_____________
< unimpurpled >
-------------
\
\
.--.
|o_o |
|:_/ |
// \ \
(| | )
/'\_ _/`\
\___)=(___/
"Thanks to the fact that the pipeline only stores what it can process in memory, this solution is very memory-efficient and lightweight. Processing a file of any size would not have changed the memory usage of this solution - the pipeline runs in effectively constant space."
This is pretty fast.
NHTSA's Office of Defects Investigation (ODI) - Recalls - Recalls Flat File
"Manufacturers who determine that a product or piece of original equipment either has a safety defect or is not in compliance with Federal safety standards are required to notify the National Highway Traffic Safety Administration (NHTSA) within 5 business days. "
Source: Data.gov
Shell it Live!
If you are repeating yourself...
alias
alias l='ls -lt'
$ l
-rw-r--r-- 1 brian staff 108847839 Mar 17 19:35 FLAT_RCL.csv
-rw-r--r-- 1 brian staff 2407 Mar 17 19:16 RCL.txt
-rwxr-xr-x@ 1 brian staff 108847839 Mar 17 04:46 FLAT_RCL.txt
Arguments get tacked on.
$ l FLAT_RCL.csv
-rw-r--r-- 1 brian staff 108847839 Mar 17 19:35 FLAT_RCL.csv
But there are limits...
# this would be handy!
$ alias headers = 'head -1 | tr "\t" "\n" | less -N'
# but there's no convenient way to put the filename into the first filter.
$ unalias headers
$ function headers() { head -1 $1 | tr "\t" "\n" | less -N }
# now we're cookin' with fire!
headers FLAT_RCL.txt
Another example...
$ function httphead () {
wget -O - -o /dev/null --save-headers $1 | \
awk 'BEGIN{skip=0}{ if (($0)=="\r") {skip=1;}; \
if (skip==0) print $0 }'
}
$ httphead www.github.com
HTTP/1.1 200 OK
Server: GitHub.com
Date: Tue, 18 Mar 2014 00:56:13 GMT
Content-Type: text/html; charset=utf-8
Status: 200 OK
Cache-Control: private, max-age=0, must-revalidate
Strict-Transport-Security: max-age=31536000
...snip...
Let's say we wanted to see what HTTP headers Google and Github have in common.
SHELL IT LIVE
colordiff --side-by-side \
<(httphead google.com | cut -d ":" -f 1 | sort) \
<(httphead github.com | cut -d ":" -f 1 | sort) | \
grep -v "[<>|]"
xargs
Your poor man's map function.
# this will pass all files to tail -1 together
find . -name "*.csv" | xargs tail -1
# this will call tail -1 on each file individually
find . -name "*.csv" | xargs -I {} tail -1 {}
You could live in the shell if you wanted to...
vim
emacs
lynx
(For the masochistic.)
Wrap-up!
Additional Resources
- Pipes and Filters
- Unix Commands I Abuse Every DAy
- Software Carpentry - The Shell
(Thanks, Jason Orendorff!) - More Shell, Less Egg
- On McIlroy
THE END
BY Brian Dailey / @byeliad
Questions?
dailytechnology.net/talk-cli-intro
Thanks to Jason Orendorff, Jason Myers, and others for reviewing.